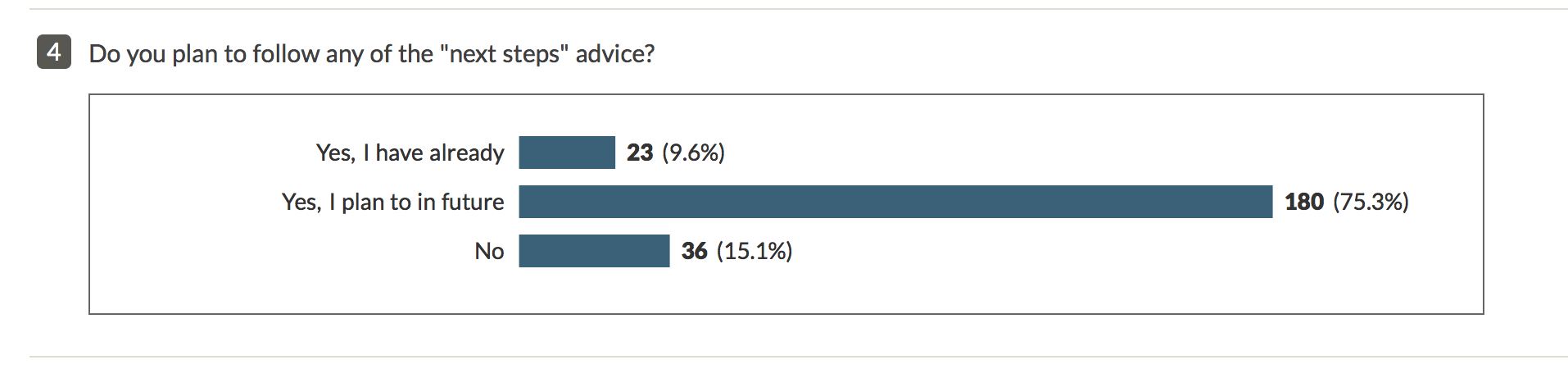
We have just been through an interim analysis of feedback from staff users of the Digital discovery tool. Thank you for directing so many staff to complete the feedback form – 225 general staff and 150 teaching staff have done so already, and it has been an invaluable resource.
 The feedback so far has been very positive, with some interesting perceptions that we will report in the next blog post. This post is about some of the changes we have made to the content of questions. It also seems like a good opportunity to explain a bit more of the thinking that goes into the three question types, and into the reasons for designing the discovery tool in the way we have. There is some general information at the top of the post, and more detail further down for those who are interested in the different question types.
The feedback so far has been very positive, with some interesting perceptions that we will report in the next blog post. This post is about some of the changes we have made to the content of questions. It also seems like a good opportunity to explain a bit more of the thinking that goes into the three question types, and into the reasons for designing the discovery tool in the way we have. There is some general information at the top of the post, and more detail further down for those who are interested in the different question types.
Development rather than testing
At the start of the design process we had to make a significant decision. We could have written ‘testing’ questions, as in a typical assessment test, to find out what users really understand about digital applications and approaches. But we decided to write ‘developmental’ questions instead. These are designed to develop understanding, for example by making clear what ‘better’ (deeper, better judged) performance looks like. Rather than hiding the ‘right’ answer, they make transparent what expert digital professionals do and ask users to reflect and report: ‘do I do that?’
We have gone down this road partly because we are not convinced that testing abstract understanding is the best indicator of actual practice, and partly because this approach is more acceptable to end users. Staff want to be treated as professionals, and to take responsibility for assessing and moving forward their own practice. Also, we are not designing in a platform that supports item-by-item matching of feedback to response. So it’s not possible for the feedback itself to be closely matched to users’ input – as it would be in an assessment system – and our questions themselves have to do a lot of the work.
This has important implications for the meaning of the scoring ‘bands’ that we use to assign feedback to users (more of this shortly).
Where do the question items come from?
Essentially, to design the questions we first developed a wide range of real-world activities that digital professionals do. We’ve tested those out with expert panels, and also against the relevant professional profile(s) – which have had professional body involvement.
Of course we could just have presented these activities in a random order, and this was an early design idea. But the digital capabilities framework already had good recognition in the sector, and we needed a navigational aid. So in the case of the generic assessments (for staff and students) we allocated activities to the different framework areas, e.g. ‘data literacy’. In the case of role-specialist assessments, we used specialist requirements from the relevant profile, such as ‘face-to-face teaching’ or ‘assessment and feedback’ in the case of the teaching assessments.
We then took one activity that was central to the area in question and framed it as a ‘confidence’ question (‘How confident do you feel about doing x?’). We developed another activity into a mini-scenario or example to create a ‘depth’ question, with four levels of response possible (‘Which of these best reflects your response?’). Six further activities became options in a ‘breadth’ question (‘Which of these can you do? Select any or all that apply to you’). This provides us with three questions, 8 activities, for each area of practice. There is more about the different question types below.
We have not statistically tested to discover whether responses to all three questions in one area hang together to create a distinct and separate factor. There is the opportunity to do that with system data at this point, but our first aim was to create a navigable user experience – making sense and generating helpful feedback – rather than to validate a model.
Ideally the feedback we give to users would relate to their responses for each of the eight different activities. Without this option, we have used scoring bands to allocate roughly appropriate feedback to users, based on their responses to the three questions. It’s not exact, and some users have picked that up. However, most users rate the quality of feedback highly – it has the most positive comments of any feature – so we know we are getting it more or less right. We hope we have dealt with the lack of specificity by offering a range of ‘next steps’ that participants can choose from, according to their own interests and self-assessed development needs.
You’ll understand from this that scoring is an artefact of the system we are using and the design choices we have made within it, not an objective measure of any kind.
We were pleased when we analysed system data from the first two months of use to see that in all but three of the 45 generic staff questions, and in all the teaching staff questions, the scoring bands were evenly distributed. This means that the questions were doing a good job of discriminating among staff according to their (self-declared) expertise, and the full range of scoring bands and feedback was being used. Three questions had median scores outside of the normal range, and a couple of sections elicited comments that users did not feel their feedback reflected their actual capability (‘information literacy’ was one). Rather than changing the underlying scoring model for these questions, we decided it was more appropriate to work on the content to try to produce a more even distribution of responses around a central median point. So if users’ scores differ from the median, that should mean something – but we can’t say that it means anything about their objective performance.
Of course users who answer the questions after the changes were made on 5 May will not be scoring in the same way as users who answered the questions before. (It’s also possible that in making the changes suggested by user feedback, we have inadvertently shifted the scoring for some other questions – we will be checking this.) This will need to be communicated to any staff who are returning to use the discovery tool again. It will also need to be taken into account when looking at data returns, since data from before and after the changes can’t be treated as one data set. This is one reason we have cautioned against using scoring data to draw any firm conclusions, particularly during this pilot period when the content is still evolving.
We hope you will convey to all the staff who took the time to complete a feedback form that we have listened to their views – and that you and they will feel that the revised questions are an improvement. This is why this pilot process is so valuable.
How have the questions changed in response to feedback?
(Some changes to wording and options is based on findings from early user testing and not from the more general feedback we gained via the user feedback forms.)
We’ve slightly changed the lay-out of questions and added some more navigational text to clarify how to answer them.
We’ve removed or clarified some terms that were not well understood. Overall we know there is a need for a glossary – ideally with examples and links. That is something Lou will be working on for the future service. We’ve also changed a couple of examples we were using for illustration. There have been many discussions about the pros and cons of examples. Some people find generic terms difficult to understand without examples: but more people object when examples are used, because they favour some applications or approaches over others that are equally valid. Examples can confuse further: ‘if I don’t use that tool, I’m obviously not doing it (right)’. Overall we have gone light on examples, and we hope users’ understanding of terms will improve when we have a detailed glossary we can link to.
We have tried to focus more on activities users do at work, in an educational organisation (college or university). There were some negative comments about references to digital practices beyond this space. However, because of the need to cover a very wide range of roles – and because some roles don’t allow people to express digital capabilities they actually have – we can’t avoid offering some examples from beyond a narrowly-defined work role. For example, one of the activities under ‘digital identity’ is ‘manage social media for an organisation, group or team‘, and under ‘data literacy’ we have ‘judge the credibility of statistics used in public debate’. This is to allow users who don’t manage social media or evaluate statistics as part of their job to reflect on whether they have these capabilities anyway – perhaps gained in their personal life or another role. And indeed to consider whether these activities might be useful to them.
We’ve changed several references to social media, as a number of users objected to what they felt was an underlying assumption that social media would or should be used, and that this was a positive sign of capability. There are still several ways that users can show they are making wise judgements about the appropriateness of social media.
We’ve tried our best to use prompts that reflect capability (‘could do’, ‘would do’, ‘have ever done’) rather than current practice (‘do’, ‘do regularly’), which may be constrained by organisational issues or may reflect judgements not to use. However, we are also mindful that self-reported practice (‘I actually do this’) is usually more accurate than self-reported ability (‘I could do this if I wanted to’). Where we feel it is justified, we have continued to ask about actual use. So long as users understand that they are not being judged, it seems appropriate for the questions and feedback to indicate areas where they are not as capable as they might be if their organisation were more supportive of different practices, or their job role offered more digital opportunities.
There have been changes to the teaching questions, again to focus on pedagogical judgement rather than digital practice. There are now quite a number of caveats e.g. ‘if appropriate to my learners‘, which were suggested by more expert users. Of course we always listen to our experts (!) but as designers we’re aware that introducing caveats like this makes the questions longer and more complex, creating more cognitive load for users, and potential annoyance. We will monitor completion rates to see if this is a problem.
We have particularly reviewed the assessment questions and the online learning questions to be sure we are covering the very wide range of good practice in these areas.
There follows more detail on specific question types and the changes we have made to each of these.
‘Confidence’ questions
Why have we included questions that ask users ‘How confident do you feel about..?’ when we know that self-assessed confidence is generally unreliable? We do this at the start of each element to give users an orientation towards the questions that follow – ‘this is the area of practice we are looking at next’ – and a sense that they are in control. By trusting users to rate themselves, we are both reassuring them that they are not being ‘tested’, and asking them to be honest and searching in their responses. We have weighted the scoring for this question at a low level to reflect users tendency to answer inaccurately – though in fact when we came to compare confidence scores with scores on the other two question types in the same area of practice, there was a positive match.
In feedback, quite a number of users mentioned the tone of these questions positively. 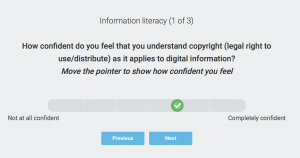 However, some felt that they were too ‘subjective’, or ‘vague’. We have tried to deal with this in the update by focusing some questions more tightly on specific practices within the overall area we are looking at. So for example in the generic staff set, under ‘digital creativity’ we ask: ‘How confident are you creating digital content e.g. video, audio, animations, graphics, web pages?’ In the teaching set, under ‘learning resources’, we ask ‘How confident are you about using digital resources within the rules of copyright?‘ We have to find a practice that is generic enough to be available to staff in a wide variety of different roles, but specific enough for the response to feel rooted in a real-world activity.
However, some felt that they were too ‘subjective’, or ‘vague’. We have tried to deal with this in the update by focusing some questions more tightly on specific practices within the overall area we are looking at. So for example in the generic staff set, under ‘digital creativity’ we ask: ‘How confident are you creating digital content e.g. video, audio, animations, graphics, web pages?’ In the teaching set, under ‘learning resources’, we ask ‘How confident are you about using digital resources within the rules of copyright?‘ We have to find a practice that is generic enough to be available to staff in a wide variety of different roles, but specific enough for the response to feel rooted in a real-world activity.
We have had internal discussions about whether to move the confidence questions to the end of each set, or to remove them altogether. For now they stay where they are.
‘Depth’ questions
These questions are the most difficult to write and currently the most troublesome to end users. There are some ongoing issues with how they are presented on screen, and we are looking into whether any improvements are possible, but for now we have reworded the questions to make the steps to answer them as clear as we can.
These questions offer a short situation or example. Users select the one response that best matches what they would do or what expertise they have. The lay-out of the question reflects the progression logic: the first option reflects the lowest level of judgement or expertise, and the fourth option reflects the highest. There is no trickery here. We describe how progressively more expert practitioners think or act, and ask users to report where they sit on that scale. (At the moment, the visual cues do not make clear that it is a scale, or that higher levels of judgement encompass a nd include the lower ones.)
nd include the lower ones.)
Beyond the difficulties some users had in ‘reading’ the answer logic for these questions, it is clear that we have to get the progression logic right in each case. When people disagree with our judgement about what is ‘more expert’, they don’t like these questions. When they agree, they say they are ‘nuanced’, ‘thoughtful’, and ‘made me think‘. We know that our users expect us to reflect issues of judgement and discrimination (‘how well is
digital technology being used?’) at least as much as extent of use (‘how many different digital tools?’). So we know these questions have to be in there. They have to reflect important issues of digital thinking or mindset, and we have to get them right – in a very small number of words!
Our recent updates aim to clarify the focus on judgement and experience rather than extent of use. And we have added modifiers such as ‘when appropriate’ or ‘if appropriate for your learners’ (teaching staff) to emphasise that we don’t believe technology is always the answer – but good judgement about technology is. This creates more words on the screen, which will put off some users, but we want our champions to feel that our words represent thoughtful
practice and not a shallow checklist of skills.
‘Breadth’ questions
 These are in many ways the most unproblematic. They offer a range of digital activities that staff may do already, may want to do, or may not even have thought about. As before, we try to clarify that we don’t think digital practices are always the best, but we do want people to extend their repertoire so they have more experience of what does (and doesn’t) work. We try to use wording that values skills users have, even if they can’t use them currently due to their role or organisational context. We have tried to avoid very role-specific activities, but not to preclude the possibility that people might develop some professionally-relevant skills in their personal lives, or take on tasks from ‘other’ roles that they enjoy. We include fairly basic activities that many users will be able to select, and quite advanced activities that offer something to aspire to. The ‘nudge’ information is obvious: think about doing some of these things if you don’t or can’t already.
These are in many ways the most unproblematic. They offer a range of digital activities that staff may do already, may want to do, or may not even have thought about. As before, we try to clarify that we don’t think digital practices are always the best, but we do want people to extend their repertoire so they have more experience of what does (and doesn’t) work. We try to use wording that values skills users have, even if they can’t use them currently due to their role or organisational context. We have tried to avoid very role-specific activities, but not to preclude the possibility that people might develop some professionally-relevant skills in their personal lives, or take on tasks from ‘other’ roles that they enjoy. We include fairly basic activities that many users will be able to select, and quite advanced activities that offer something to aspire to. The ‘nudge’ information is obvious: think about doing some of these things if you don’t or can’t already.
What next?
We are always interested in your views on the questions and other content. The user feedback forms will remain live until the end of the pilot project and we expect to make some further updates to content at that point. Please keep asking your users to access this from the potentially platform.
If you are an institutional lead, you will shortly have an opportunity to give us feedback via your own detailed evaluation survey. You can also give us comments and feedback at any time via our expert feedback form – please direct other stakeholders and interested users to do this too.